

GLM-5.2 is an excellent coding model. Claude Code is an excellent coding-agent harness.
You can combine them.
This guide shows three practical ways to run GLM-5.2 inside Claude Code:
- OpenRouter, which is the best starting point if you want one routing layer and cost visibility.
- Z.AI direct, which is the cleanest provider-native setup.
- A local or internal proxy, which is the advanced setup for teams that need custom routing.
The cost case is straightforward. GLM-5.2 can be materially cheaper for coding-agent work, especially when the task does not require the most expensive default model. Optimize for cost per accepted coding outcome, not raw token volume.
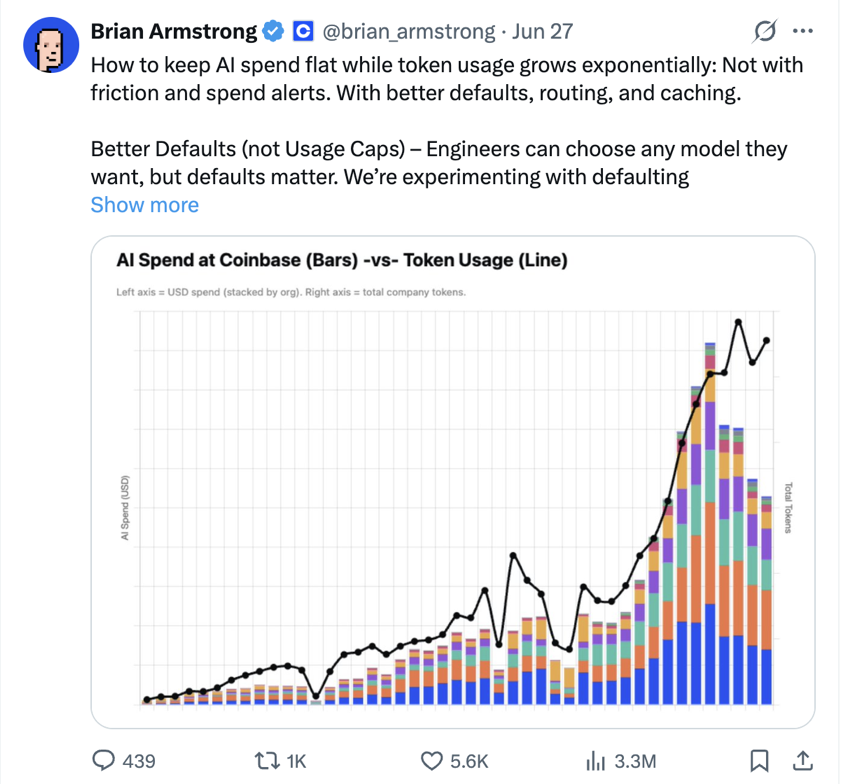
Key Findings
| Finding | What To Do |
|---|---|
| Start with OpenRouter if you want routing and cost visibility. | Use OpenRouter as the API layer, set the model to z-ai/glm-5.2, then test Claude Code tool behavior. |
| Use Z.AI direct if you want the cleanest GLM-native setup. | Point Claude Code at Z.AI's Anthropic-compatible endpoint and use the GLM-5.2 Claude Code defaults. |
| Use a proxy only if you need control. | Put a translation layer between Claude Code and OpenAI-compatible endpoints. |
| Tool calling is the main caveat. | Verify search, edit, bash, git, tests, and long streaming responses before team rollout. |
| Measure cost per finished task. | Count retries, failed tool calls, review rewrite, and abandoned sessions. |
Evidence and Methodology
OpenRouter lists the GLM-5.2 model ID as:
z-ai/glm-5.2OpenRouter also lists GLM-5.2 with a 1M-token context window and pricing of $0.95 / $3 per 1M input/output tokens at the time of writing. That makes it a serious candidate for cost-sensitive coding-agent work.
List price is only the starting point. In a public GLM vs Opus cost thread, Sridhar Ramaswamy described a benchmark where GLM used about twice the tokens but still cost roughly half as much.
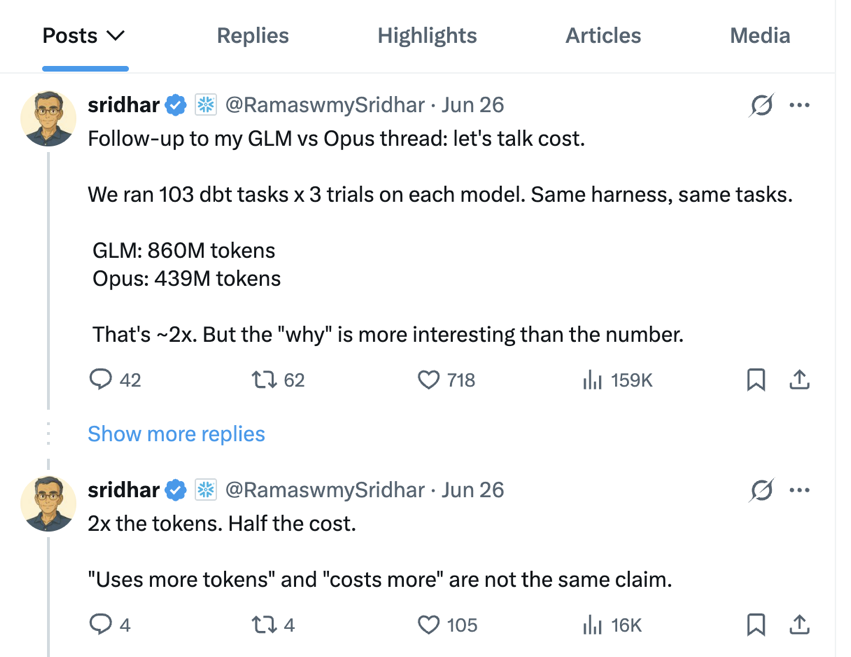
More tokens can still cost less.
For coding agents, measure the full session:
| Metric | Why It Matters |
|---|---|
| Cost per accepted task | The session produced work the engineer kept. |
| Retry-adjusted cost | Cheap failed attempts are still waste. |
| Tool-call success | Claude Code depends on tool reliability. |
| Review-adjusted cost | Low-quality diffs push cost onto reviewers. |
| Rework-adjusted cost | Code that gets rewritten was not cheap. |
Concrete Operator Scenario
An engineering team already uses Claude Code every day. Engineers like the harness and want to keep it. Finance sees AI spend rising and asks whether there is a cheaper default for some classes of work.
The team keeps Claude Code and changes the model route.
They test GLM-5.2 for:
| Work Type | Fit |
|---|---|
| Repo exploration | Strong fit. Long context helps. |
| Routine implementation | Strong fit after verification. |
| Test generation | Good fit with review discipline. |
| Refactors | Good fit when tests are solid. |
| Security-sensitive code | Use carefully. Keep stricter review. |
| High-risk architecture | Compare against the strongest model before switching. |
This is the operating model: keep Claude Code, route suitable work to GLM-5.2, and keep premium models for tasks where they earn their cost.
Measurement Approach
Run a small benchmark before changing defaults.
Use the same repository, prompt, acceptance criteria, and test commands across your current Claude Code model and GLM-5.2.
Track:
| Measurement | Pass Criteria |
|---|---|
| Setup works | Claude Code starts and reports the expected model route. |
| Search works | It can inspect files and find relevant code. |
| Edit works | It can produce a clean patch. |
| Bash works | It can run commands and handle failures. |
| Tests work | It can run tests and fix failures. |
| Cost improves | Total session cost is lower after retries. |
| Review quality holds | The diff is not creating extra human cleanup. |
Treat lower model pricing as a hypothesis. The benchmark passes when cost per accepted task drops.
Path 1: OpenRouter
Use this path first if your team wants one API layer for model routing, usage visibility, and spend controls.
Create an OpenRouter API key, then run Claude Code with OpenRouter as the base URL:
export ANTHROPIC_BASE_URL="https://openrouter.ai/api"
export ANTHROPIC_AUTH_TOKEN="$OPENROUTER_API_KEY"
export ANTHROPIC_MODEL="z-ai/glm-5.2"
claudeFor persistent setup, add it to ~/.claude/settings.json:
{
"env": {
"ANTHROPIC_BASE_URL": "https://openrouter.ai/api",
"ANTHROPIC_AUTH_TOKEN": "YOUR_OPENROUTER_API_KEY",
"ANTHROPIC_MODEL": "z-ai/glm-5.2"
}
}Then restart Claude Code and run:
/statusConfirm that Claude Code is using the expected route. Then run a real coding task.
OpenRouter caveat: its Claude Code documentation says Claude Code support through OpenRouter is guaranteed only with Anthropic first-party providers. GLM-5.2 may work through OpenRouter, but you should treat it as a compatibility test until your own file-editing, bash, test, and tool-calling checks pass.
Use OpenRouter when you want:
- centralized cost reporting,
- one key across multiple providers,
- budget controls,
- model comparison,
- routing and fallback.
Use it for team-wide Claude Code defaults only after tool calling is verified.
Path 2: Z.AI Direct
Use this path if you want the cleanest GLM-native setup.
Z.AI documents an Anthropic-compatible Claude Code endpoint:
https://api.z.ai/api/anthropicAdd this to ~/.claude/settings.json:
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "YOUR_ZAI_API_KEY",
"ANTHROPIC_BASE_URL": "https://api.z.ai/api/anthropic",
"API_TIMEOUT_MS": "3000000",
"CLAUDE_CODE_AUTO_COMPACT_WINDOW": "1000000",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.5-air",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-5.2[1m]",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5.2[1m]"
}
}Restart Claude Code:
claudeCheck:
/statusThis is the safest GLM-specific path because it uses an Anthropic-compatible endpoint instead of forcing Claude Code through an OpenAI-compatible API.
Path 3: Local or Internal Proxy
Use this path if your team already runs an AI gateway or needs custom routing.
Claude Code expects Anthropic-style behavior. Some GLM endpoints and gateways expose OpenAI-compatible Chat Completions instead. Put a proxy between Claude Code and an OpenAI-compatible endpoint so the request and tool-call formats are translated correctly.
The shape is:
Claude Code
-> Anthropic-compatible proxy
-> OpenAI-compatible GLM endpoint
-> GLM-5.2Use this setup when you need:
- model aliases,
- team-level attribution,
- internal logging,
- policy controls,
- caching,
- retries,
- fallback routing.
This is the most flexible option and the easiest one to break. Test it carefully.
Caveats And Failure Modes
Most failures come from the adapter layer.
| Caveat | What Can Go Wrong | Fix |
|---|---|---|
| Tool schemas | Claude Code tool calls may not survive translation. | Prefer Anthropic-compatible routes and test real tool use. |
| Streaming | Long edits can break if the gateway buffers or reshapes output. | Test large diffs and failing-test loops. |
| Context | 1M context is useful but can increase spend. | Use large context for repo-scale tasks, not every small change. |
| Retries | Failed attempts erase savings. | Track retry-adjusted cost. |
| Review burden | Cheap code can become expensive in review. | Track accepted diffs, not generated diffs. |
| Auth precedence | Existing Claude Code auth can confuse routing. | Check /status, clear conflicting env vars, restart Claude Code. |
The practical rule: if search, edit, bash, git, tests, and long streaming responses work, the setup is worth benchmarking. If any of those fail, fix the route before judging GLM-5.2.
What To Do Next
Start with OpenRouter if you care about routing and visibility. Start with Z.AI direct if you want the cleanest GLM-specific setup.
Run this five-task test:
- Ask Claude Code to inspect a real repo and explain the relevant files.
- Ask it to make a small implementation change.
- Ask it to update or add tests.
- Ask it to run tests and fix failures.
- Ask it to summarize the final diff and risks.
Compare GLM-5.2 against your current default model on:
- total session cost,
- retry count,
- latency,
- tool-call success,
- test success,
- review rewrite,
- accepted outcome rate.
If GLM-5.2 cuts cost without increasing retries or review burden, make it the default for those task classes. Keep stronger models for work that needs them.
Related Pages
- What Is AI-Native Developer Intelligence?
- What Is Engineer-Agent Effectiveness?
- What Is Agent Readiness?
- What Is Prompt Fluency?
- What Is Token Cost Effectiveness for AI Coding?
FAQ
Can I use GLM-5.2 inside Claude Code?
Yes. Use OpenRouter, Z.AI's Anthropic-compatible endpoint, or a proxy that translates Claude Code's Anthropic-style requests.
Which setup should I try first?
Try OpenRouter first if you want routing and cost visibility. Try Z.AI direct first if you want the simplest GLM-specific route.
What is the OpenRouter model ID?
Use z-ai/glm-5.2.
What is the biggest caveat?
Tool calling. Verify file search, edits, bash commands, tests, git, and long streaming responses before using the setup for serious work.
Can this really cut costs by up to 50%?
Yes, for the right task classes. The savings depend on model pricing, retries, context size, cache behavior, and review quality. Measure cost per accepted coding task.