


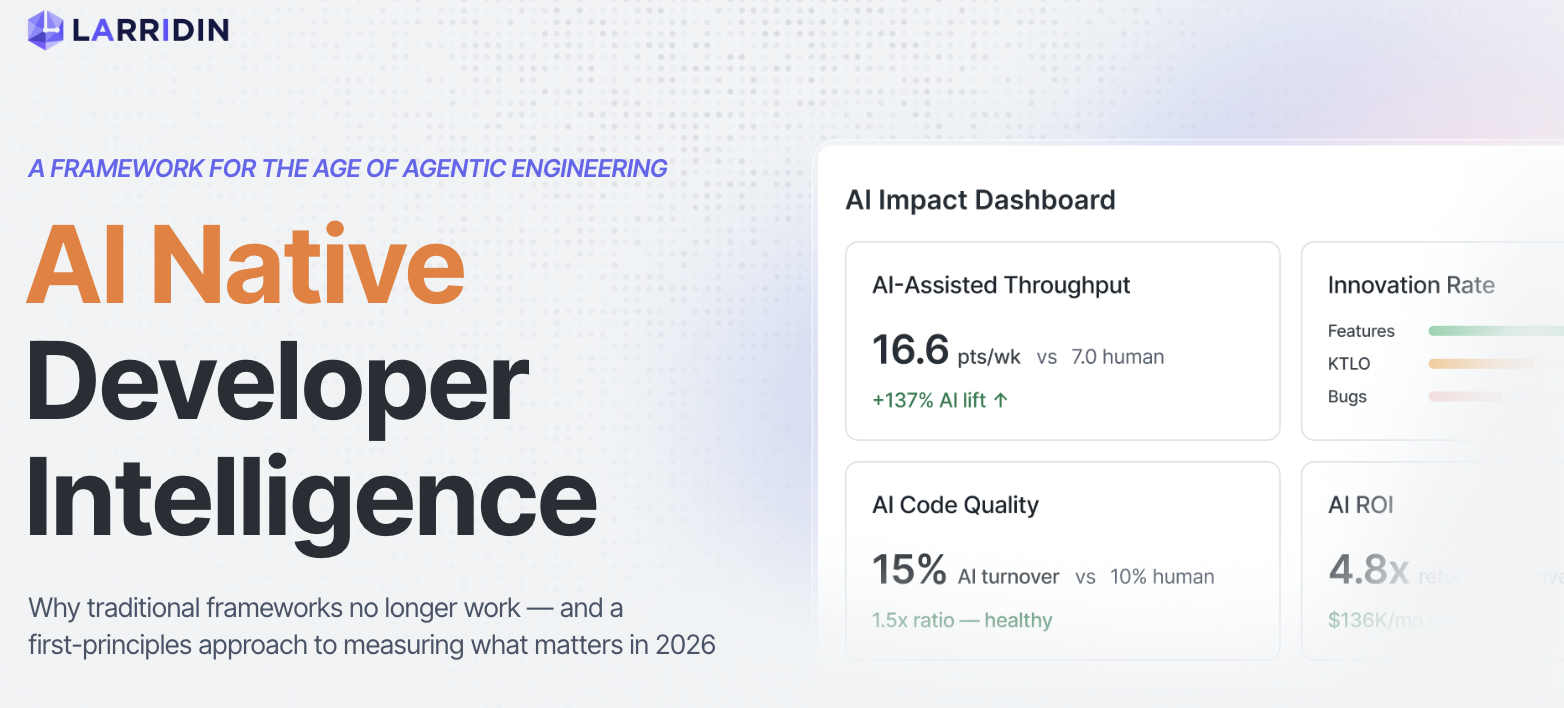
AI-Native Developer Intelligence helps engineering leaders unlock the full potential of AI-empowered engineering teams. It measures engineer-agent effectiveness, environment readiness, workflow bottlenecks, and token cost effectiveness, then connects those signals to delivery, quality, reliability, developer sentiment, DORA, and SPACE.
Traditional engineering metrics still matter. Deployment frequency, lead time, reliability, collaboration, and developer experience remain useful signals. The issue is that they were not designed to explain a team where code is increasingly produced, reviewed, tested, and revised through human-agent collaboration.
AI-native teams need a measurement layer that can answer a different set of operating questions:
- Are engineers actually working with coding agents, or only experimenting with them?
- Are agent sessions producing accepted engineering outcomes?
- Is the repository ready for agentic development?
- Did AI make coding faster while moving the bottleneck to review, testing, CI, or reliability?
- Is token spend producing durable software, or just more generated output?
That is the role of AI-Native Developer Intelligence.
Key Findings
| Question | What AI-Native Developer Intelligence Measures | Why It Matters |
|---|---|---|
| Are engineers getting leverage from agents? | Engineer-agent effectiveness, prompt fluency, session steering, verification discipline, and task outcomes. | Usage alone does not prove productivity. The important question is whether AI-assisted work becomes accepted, durable engineering output. |
| Is the environment ready for AI-native work? | Agent readiness across build systems, tests, documentation, CI feedback, task discovery, observability, and security practices. | Agents perform better when repositories are easy to understand, test, and change safely. |
| Where did the bottleneck move? | PR cycle time, time to first review, review quality, rubber-stamp rate, pushback rate, rework, and workflow friction. | AI often accelerates code generation before the rest of the engineering system is ready to absorb the output. |
| Is token spend efficient? | Session cost, token efficiency, cache hit rate, cost per accepted outcome, and platform-level usage. | Token volume is not the same as business value. Leaders need to know whether spend converts into accepted work. |
| Is delivery improving safely? | AI code share, complexity-adjusted velocity, code rework rate, AI Slop Index, review quality, DORA, reliability, and incidents. | Faster shipping only matters if quality, maintainability, and reliability do not degrade. |
| Are engineers experiencing AI as leverage? | Developer sentiment, collaboration, flow, satisfaction, perceived productivity, and SPACE-style signals. | AI can increase throughput while increasing review burden, interruptions, or cognitive load. |
Evidence and Methodology
AI-Native Developer Intelligence is a category definition, not a single metric. It combines AI-native signals with established engineering measurement.
DORA gives engineering leaders a proven language for software delivery performance: deployment frequency, lead time for changes, change failure rate, and recovery time. SPACE gives teams a broader lens across satisfaction, performance, activity, communication, and efficiency. Developer sentiment captures how engineers experience the system, not only what the system produces.
Those frameworks are still useful. They are incomplete by themselves in an agentic engineering environment.
The missing layer is the work between AI adoption and engineering output:
| Measurement Layer | Examples | What It Explains |
|---|---|---|
| Agent usage | Active users, platforms used, sessions, AI-assisted PRs, AI code share. | Whether AI tools are being adopted. |
| Engineer-agent effectiveness | Prompt quality, session steering, verification discipline, task outcomes, accepted work. | Whether engineers are using agents well. |
| Environment readiness | Tests, build speed, documentation, repo structure, CI feedback, task discovery, security controls. | Whether agents can operate safely inside the codebase. |
| Workflow bottlenecks | PR review delay, rubber-stamp rate, rework, approval-to-merge delay, CI friction. | Where faster coding gets stuck. |
| Token cost effectiveness | Session cost, cache efficiency, tokens by platform, cost per accepted outcome. | Whether AI spend is turning into engineering leverage. |
| Delivery and quality | DORA, complexity-adjusted velocity, AI Slop Index, code rework, incidents, reliability. | Whether the system ships more useful software without creating hidden risk. |
| Developer sentiment | Flow, collaboration, satisfaction, perceived productivity, friction, trust in AI output. | Whether AI improves the human experience of engineering work. |
Larridin's point of view is that AI-native measurement should connect these layers. Looking at any one layer in isolation creates blind spots.
High adoption with poor task outcomes means teams are spending time with AI but not getting durable leverage. Higher throughput with rising code rework means the organization may be converting token spend into future cleanup work. Strong DORA metrics with deteriorating sentiment can mean the system is shipping at the cost of review fatigue or context switching. Good sentiment with no delivery change may mean AI feels helpful locally but has not changed organizational capacity.
AI-Native Developer Intelligence is designed to show those relationships.
Concrete Operator Scenario
An engineering leader approves enterprise access to coding agents. Three months later, the dashboard looks mixed.
AI usage is high. Engineers are trying multiple tools. Pull request volume is up. Some teams report that they feel faster. Finance can see token spend rising across platforms.
But the leadership team still cannot answer the hard questions:
- Which teams are actually turning agent work into accepted product changes?
- Which repositories are agent-ready, and which ones waste sessions on setup, broken tests, or missing context?
- Did coding speed improve, or did review time absorb the gain?
- Are engineers verifying AI output, or are reviewers becoming the quality gate for generated code?
- Is the company buying leverage, or buying a larger queue of work to inspect and rewrite?
This is the operator scenario AI-Native Developer Intelligence is built for. It does not stop at "AI adoption is up." It shows whether adoption is becoming productive capacity, and where the current system is limiting that capacity.
Measurement Approach
Start with four AI-native pillars, then connect them to established engineering outcomes.
1. Measure Engineer-Agent Effectiveness
Track whether agent sessions produce useful engineering outcomes. The useful signals are not just prompts sent or tokens consumed. They include prompt clarity, session steering, verification discipline, task outcomes, accepted PRs, and whether generated work survives review and follow-up changes.
Good measurement asks: did the engineer and agent produce work the engineering system accepted?
2. Measure Environment Readiness
Agents inherit the quality of the engineering environment. A repo with fast tests, clear documentation, stable build commands, searchable task context, strong observability, and consistent patterns gives agents a better operating surface. A repo with flaky tests, ambiguous ownership, slow CI, and undocumented conventions turns agent sessions into troubleshooting loops.
Good measurement asks: is this environment ready for agentic development?
3. Measure Workflow Bottlenecks
AI can increase the rate of code creation before it increases the rate of safe delivery. That means the bottleneck often moves to review, test repair, CI, merge queues, architecture review, security review, or incident response.
Good measurement asks: where is AI-generated speed being absorbed by the system?
4. Measure Token Cost Effectiveness
Token spend should be tied to engineering outcomes, not treated as a proxy for progress. A team can spend heavily on retries, dead-end sessions, unused generated code, or work that gets rewritten. Another team can spend less and produce accepted, durable changes because its context, prompts, cache usage, and verification loops are better.
Good measurement asks: what accepted engineering outcome did this token spend buy?
5. Connect AI-Native Signals to DORA, SPACE, Quality, Reliability, and Sentiment
The AI-native layer should not replace established metrics. It should explain them.
If lead time improves, AI-Native Developer Intelligence should show whether the improvement came from better agent collaboration, better environment readiness, or reduced workflow friction. If change failure rate worsens, it should show whether AI code quality, review depth, or verification discipline changed. If developer sentiment drops, it should show whether AI increased review burden, context switching, or uncertainty about generated code.
The practical operating model is:
| If this changes | Look at these AI-native signals |
|---|---|
| Lead time improves or worsens | Agent effectiveness, PR cycle time, CI friction, review delay. |
| Deployment frequency changes | Complexity-adjusted velocity, workflow bottlenecks, environment readiness. |
| Change failure rate worsens | AI Slop Index, verification discipline, review quality, code rework. |
| Recovery time worsens | Observability readiness, incident signals, ownership clarity. |
| Developer sentiment changes | Prompt fluency, review burden, workflow friction, collaboration, perceived productivity. |
| AI spend rises | Token efficiency, session cost, cost per accepted outcome, cache hit rate. |
Caveats And Failure Modes
AI-Native Developer Intelligence can be misused if it becomes individual surveillance. The goal is not to rank engineers by AI usage, token spend, prompt count, or generated code volume. Those incentives produce performative adoption.
The better use is system diagnosis:
| Failure Mode | Better Question |
|---|---|
| "Which engineers use AI the most?" | "Which teams turn AI-assisted work into accepted, durable outcomes?" |
| "Which team has the highest AI code share?" | "Where is AI code share improving capacity without increasing rework or slop?" |
| "How do we reduce token spend?" | "Which spend produces accepted output, and which spend disappears into retries or unused work?" |
| "How do we force every repo to use agents?" | "Which environments are ready for agents, and what blocks the others?" |
| "Can AI replace our existing metrics?" | "How does the AI-native layer explain delivery, quality, reliability, sentiment, DORA, and SPACE?" |
There is also a timing caveat. Some benefits show up quickly, such as faster draft code or faster local exploration. Other costs show up later, such as rework, review fatigue, reliability incidents, and architectural drift. AI-native measurement should combine leading signals and lagging outcomes.
Finally, no category definition should pretend that every team can reach the same leverage curve. Highly tested product code, legacy systems, infrastructure work, data pipelines, security-sensitive code, and exploratory prototypes have different risk profiles. The point is to identify the constraint for each team, not to impose one universal productivity number.
What To Do Next
Start by separating AI adoption from AI leverage.
Adoption asks whether engineers are using AI tools. Leverage asks whether those tools are increasing accepted engineering capacity without creating hidden quality, reliability, or cost risk.
For most engineering organizations, the first operating dashboard should include:
| Area | Minimum Useful Signals |
|---|---|
| Engineer-agent effectiveness | Prompt quality, session steering, verification discipline, task outcomes, accepted work. |
| Environment readiness | Testability, CI feedback speed, documentation, build reliability, task discovery, security and observability readiness. |
| Workflow bottlenecks | PR cycle time, review latency, rubber-stamp rate, pushback rate, approval-to-merge delay, rework. |
| Token cost effectiveness | Session cost, token efficiency, cache hit rate, cost per accepted outcome. |
| Delivery and quality | AI code share, complexity-adjusted velocity, AI Slop Index, code rework rate, DORA, incidents. |
| Developer sentiment | Flow, collaboration, satisfaction, perceived productivity, friction, trust in AI output. |
Then ask one leadership question each week:
Where is AI increasing leverage, and where is the engineering system absorbing or wasting that leverage?
That question is the center of AI-Native Developer Intelligence.
FAQ
Is AI-Native Developer Intelligence the same as developer productivity?
No. Developer productivity is broader and older. AI-Native Developer Intelligence focuses on the measurement layer needed when engineering teams work with AI coding tools and agents. It includes productivity, but also agent effectiveness, environment readiness, token cost effectiveness, quality risk, reliability, sentiment, DORA, and SPACE.
Does AI-Native Developer Intelligence replace DORA or SPACE?
No. It adds an AI-native layer above them. DORA and SPACE remain useful for delivery, reliability, collaboration, and sentiment. AI-Native Developer Intelligence explains how AI agents, repositories, workflows, and token spend influence those outcomes.
Why is AI adoption not enough?
Adoption shows that people are using AI tools. It does not show whether those tools produce accepted work, durable code, faster delivery, better reliability, or improved developer experience. AI-native teams need to measure the path from usage to leverage.
What is engineer-agent effectiveness?
Engineer-agent effectiveness measures how well engineers work with AI agents to produce accepted engineering outcomes. It includes prompt quality, session steering, verification discipline, task outcomes, and whether AI-assisted work survives review and follow-up changes.
What is token cost effectiveness?
Token cost effectiveness measures whether AI spend is turning into meaningful engineering output. It connects session cost, token efficiency, cache hit rate, platform usage, and cost per accepted outcome instead of treating token volume as progress.