Agent Effectiveness · Powered by agent traces
Learn how the best engineers build with AI. Help everyone else catch up.
Every team has engineers who've quietly figured out how to get great work out of Claude Code, Codex, and Cursor. Larridin finds those patterns, scores them, and helps you spread them — so the whole org moves up the curve together.

A new foundation for engineering
Every team is figuring out AI-native engineering. Some are doing it faster.
Working effectively with coding agents is a new craft. The patterns that make Claude Code, Codex, and Cursor produce trustworthy work are emerging in real time, in pockets, across every team.
Most leaders can see the rough shape of it. What they don't have is a way to see which patterns are working in their own org, who's using them, and how to spread them.
Larridin's Agent Effectiveness suite is built on a new signal: agent traces. Across thousands of sessions, we surface the practices and tools that correlate with shipped code, low rework, and clean diffs.
The result is a clearer picture of what good looks like in your org, where it's already happening, and how the rest of the team can catch up — without making anyone feel watched.
01 Agent Traces
A source of truth for developer-agent interactions.
Captured sessions, indexed and connected to the PRs they shipped. The foundation everything else is built on.
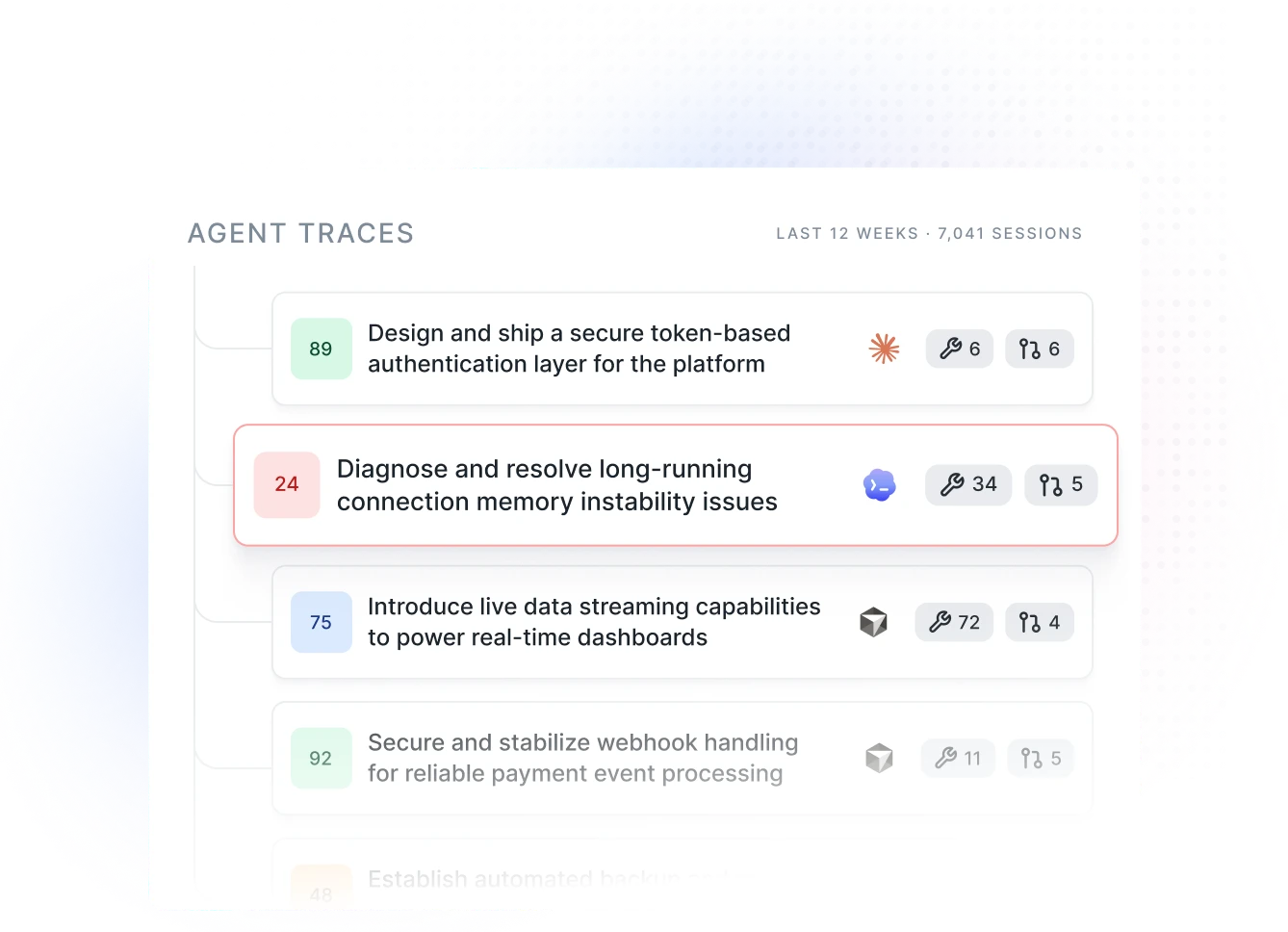

Drill into any session
From 894 sessions a week to the one worth learning from.
Every score has a trace behind it. Open any session, graded against the dimensions and tied to the PRs it produced.
22 turns. 3h 12m. Six PRs, all merged. Score: 89. What worked, what didn't, and what to repeat next time — in the engineer's own language, not management's.
This isn't surveillance telemetry. It's coaching context for the engineer who ran the session, and a way for the team to see which sessions are worth studying.
02 Agent Effectiveness
A clear baseline.
And a way to move it.
A single Agent Effectiveness Score, decomposed into the dimensions that predict whether agent work ships cleanly. Benchmarked against your own history — and the industry.

03 Spotlights
The practices and tools quietly making your team better.
Spotlights surface what's actually working in your org — the prompting patterns, the verification rituals, the skills and plugins your best engs reach for. Anonymized by default, evidence-backed always.

04 Env Readiness
A roadmap for agent-ready engineering.
Your CLAUDE.md, your skill files, your tool access, your test harnesses — all of it shapes how agents perform. Larridin synthesizes feedback across thousands of sessions into a prioritized list of fixes.

1.4m
Agent sessions analyzed across the Larridin benchmark
31%
Fewer iterations on sessions that start with explicit goals
2.7×
More follow-up fixes when sessions close without verification
2.4×
Smaller diffs when engineers constrain the edit surface up front
Customer Signal
“We had engineers writing world-class prompts and engineers still typing 'fix the bug.' Larridin showed us the gap — and the patterns to close it — without making anyone feel watched.”